mit6.s081 前言 在学习了一段时间的kernelpwn后,发现自己对于操作系统理解的还是十分浅薄,遂想浅浅深入学习一下,然后从a3大佬得知mit的操作系统课程十分之好便下定决心跟着过一遍,本来是想学习mit6.828的,但不管教材还是视频全是洋文,而我的洋文能力着实有限,幸好我找见了mit6.s081版,也在网上找见了翻译版,还有诸多博客可以答疑,感觉可行,那就开干!
准备 git 课程使用的是git进行代码管理和版本控制的,可笑我到目前为止只熟悉git close,所以再开始之前得了解一下git的命令。
看了几个小时,大概能使用了。
RSIC-V指令集 ……此处省略好多字
环境准备 我使用的是最新的ubuntu22,其实完全不用搜什么搭建环境教程的,课程的网页已经非常清楚了(他推荐的是ubuntu20.4),按照它所述一步一步来就好了,可惜我意识到这一点的时候已经浪费了一两个小时了
准备完环境最激动人心的就是实验调试环境解了,调试我参考的是这篇文章qemu xv6 使用GDB调试 - xistor’s notes
我在ls上下了断点,可见成功截住了。
从这篇文章中了解到了关于/.gdbinit文件的使用,可以向这个文件中写入gdb命令,当gdb执行的时候会在当前用户的主目录下寻找.gdbinit文件然后执行其中的命令,当你想要gdb执行不在当前用户的主目录下的.gdbinit的时候,可以在`/.gdbinit文件中导入,例如add-auto-load-safe-path /home/x/xv6-labs-2021/.gdbinit,这样做的话调试的时候就非常方便了,只需要键入gdb-multiarch`就可以直接设置架构并连接qemu了。
Lecture Lecture1 讲了一点操作系统大体作用以及结构,然后通过几个例子示范了系统调用,其中比较有收获的是fork+exec两个系统调用的搭配可以在子进程重新载入一个新程序,所以原来的子进程被完全取代,一般情况下exec函数不会返回。值得注意的是exec()后的程序的文件描述符并没有重置,还是和源程序一样,利用这个特性可以完成一些骚操作。
总体比较简单。这节课有课后实验,我看课程介绍好像可以在本地测试自己的实验并打出分数,吆西,明天看看怎么整。
Lecture3 隔离性 :操作系统提供进程和进程之间的墙隔离以及进程和硬件资源的强隔离,隔离的手段是进行抽象,提供系统调用接口。
防御性 :首先得具有错误处理能力,如果用户态进程使用系统调用的时候传入了错误的参数,内核得具有处理这种错误的能力,其次是应用程序不能破坏隔离性,这里的隔离指进程和内核的隔离,想要实现这种隔离性得需要硬件支持,比如内核模式和用户模式以及虚拟内存。
user/kernel :当cpu运行在kernel模式中就会拥有执行特权指令的权限,特权指令指直接操作硬件的指令,相对的运行在user模式只能执行非特权指令,当user模式下执行特权指令时cpu并不会真正去执行,而是从user跳到kernel,内核获得cpu控制权,然后让内核判断user是否出现了问题是否改杀死。
user->kernel :有专门的的一个指令可以从user到kernel,在x86下是syscall,在本次课程中的risc-v中是ecall,系统调用号存储在a0寄存器中。
宏内核&微内核 :相比起宏内核,微内核的诸多服务都运行在user模式,在普通进程想要使用这些服务的时候通知内核,内核再通知服务,这样会导致User和kernel的切换比较频繁。
Lecture4
对虚拟内存的看法
在我看来虚拟内存主要有两点,一点是完美的进程隔离,每个进程都有自己的页表,不会访问到其他进程的页表,二是不直接操作物理内存,也就是硬件,会比较好的保护硬件
risc-v虚拟内存简单理解:和x86很类似,也有一个mmu路由对cpu想要访问的虚拟地址进行翻译,翻译成物理内存,stap寄存器就存放着进程的页表的物理地址,也表中就存放着虚拟内存到物理内存的映射,mmu就通过访问stap来进行翻译
页表设计
在xv6操作系统中虚拟地址的前25位并没有被使用,所以尽管寄存器是64位,物理地址是56位,但其寻址空间还是2^39,在这39位中前27位是索引,后12位是偏移。
xv6的页表设计是采用三级页表的,不像x86的四级页表,之所以采用三级页表,是因为一个页表占用4k,每一个页表项所占用的内存是2^3,所以一个页表可以有2^9个页表,27/9=3,所以三个页表就完全够映射所有的索引了。
每一个页表项是64位其中最高的10位并没有被使用,因为没必要,然后后44位记录页编号(因为一共只有2^44个页),然后后10位记录一些标志,用来标识这个页表项。
TLB
采用三级页表的话得到一个具体的物理地址就需要访问访问内存三次,这是非常昂贵的,所以就像x86有缓存一样,xv6也有缓存,也叫作TLB,储存着最近访问的虚拟地址到物理地址之间的映射。
在xv6操作系统中似乎还没有实现多个进程使用同一个TLB,所以当切换进程的时候也需要刷新TLB防止映射出错。TLB还是一个硬件,并不由操作系统具体控制。
虚拟地址分布和物理地址分布
物理内存的分布都是有设计者控制的,并不由操作系统控制,在物理内存下面的那些位置并不是真实存在于内存中的,而是一种映射,比如中断或者io什么的。
为了让xv6操作系统能够比较简单简约,虚拟地址都是采用恒等映射的。
上面的虚拟地址分布似乎只是内核虚拟地址分布,内核会在free memory中为进程分配空间,下面是进程的虚拟地址分布
Lecture5 本节课程主要是讲解risc-v
在gdb中输入tui enable就能进入一个界面,在界面中输入layout asm或者layout reg,layout src就能查看汇编或者寄存器的值或者源代码了。如果想要聚焦某个窗口就可以输入focus xxx
终于学会了怎么自动开多个shell平铺到桌面了,首先输入tmux,打开一个shell,在打开一个shell就是先同时按ctrl+b然后单独按c,然后可以使用ctrl+b+p/n来切换shell窗口,可以使用ctrl b+shift+%切出新窗口,然后使用ctrl+b+o来切换窗口。
使用bt可以查看调用栈
条件断点命令b xxx if i==5
寄存器表
a0a7可以存放函数调用参数,a0a1可以存放返回值
risc-v的函数调用 和记忆中mips的函数调用很类似,risc-v中有一个寄存器专门用来记录这个函数的返回地址,当执行ret的函数,就会把pc指向ra寄存器保存的地址,但是ra寄存器只有一个,但是函数a可以调用函数b,当执行函数b的时候,ra寄存器指向函数b的返回值,但是函数b也可以调用函数c,当执行函数c的时候ra保存函数c的返回值,当返回到函数b的时候,ra还是指向了函数c的返回值,这样就会造成死循环了,所以risc-v就有一个策略,当指向非叶子函数(也就是这个函数还会调用其他函数),就会把ra保存到栈里,当函数返回的时候先把栈里的返回地址加载到ra中再执行ret指令,当执行叶子函数的时候,就不会在栈里保存ra寄存器了,当执行ret的时候直接加载ra寄存器。
Lecture6 在内核态的时候权限提升主要体现在两点,一点是可以读写控制寄存器,第二点是可以可以使用没有pte_u的页表。
这是sh程序的页表,可以清晰的看见虚拟地址到物理地址的映射,比较有收获的就是,设置了u权限的页表,用户态才可以使用,其次是陷阱帧trapframe虽然每个进程都有自己的一份,但是所有进程的虚拟地址都是一样的#define TRAPFRAME (TRAMPOLINE - PGSIZE)。
在执行ecall的时候会关闭中断,这样就不会发生进程切换了,然后在执行sret的时候又会打开中断,如果不进行其他操作,当用户态程序陷入内核态的时候并不会发生进程切换,但是这样做并不适合所有情况,当进行系统调用的时候就可以进程切换,打开中断和关闭中断的函数分别是intr_on()和intr_off(),当执行完系统调用的时候又会关闭中断。
Lecture8 页面错误(page faults)
其实可以利用页面错误配合虚拟内存来完成好多有意思的事情,比如说fork的写时复制或者惰性分配。
在发生页面错误时我们可以知道三个信息,首先是错误地址,得知道错误地址才能去处理他,这个错误地址就保存在stval寄存器中,第二点就是得知道页面错误的类型,这个类型就存储在scause寄存器中。第三件点得知道引起页面错误的指令的虚拟地址,这个地址就存储在sepc中。
惰性分配
惰性分配实际就是一个空头支票,并不分配物理内存和映射,而是先增大p->sz,当使用这段内存的时候才根据scause的值确定页面错误类型然后分配内存并且映射,所以在srbk中并不需要映射,而是增大p->sz的值就可以了,大概思路如下图代码,比较好理解
但是这样又会导致另一个错误,当惰性分配后,可能的情况就是有些真的分配了,有的没有分配,当释放这个进程的内存的就是后就会发生如下bug
简单的解决方案就是释放进程内存的时候条件放的宽松一点,原本的uvnunmap是如果检测到了不存在的映射直接panic,我们可以修改成continue
很熟悉的bss段也可以利用惰性分配,类似下图,先让bss全部映射到一个只有读权限的页面,当有一个地址想要写入内容的时候就会触发页面错误,进而可以给他分配一个新的页面。
COW
copy on write,也就是fork的写时复制技术,当fork的时候,把父子进程都映射到原先父进程的物理内存上,但是他们都是r。
然后当子进程想要在这段内存中写入内容时就会发生页表错误,然后可以重新申请一个页面,把发生错误的页面的内容复制到新申请的页面上,然后把这个页面映射到子进程中,原先错误的虚拟地址就指向了这个新的页面,然后把父进程的权限变成rw,然后重新执行发生页面错误的指令。
但是如果使用往一个只读页面中写入内容来判断是否是写时复制其实是不准确的,因为有些页面本来就是只读内容,这样就会破坏这些页面的内容了。在pte中还存在一位叫做RSW,可以把这一位设置成是否是cow页面的标志。
上述的cow策略并不完美,当一个父进程fork了多个子进程之后,父进程exit的话显然不能直接释放父进程的页面,因为所有子进程都指向这些页面,所以得给每个页面加个引用计数,当计数为0的时候才会真正释放这个页面。
按需分配
按需分配是内存扩展的精髓,当在内存中加载文件时并不是全部都加载进去,而是按需加载,然后当内存用完之后再驱逐一些近期不用的页面腾出空间。
Lecture9 book read 这一节是关于中断的,以前总是对中断模模糊糊的,不是很清楚,通过阅读本节内容和网上的资料,终于对中断有了一个较为清晰的概念了。
中断其实就是在CPU正在做某件事的时候,收到了通知告诉CPU你要放下手头现在做的事,去处理另一件事(当然这个是立即处理还是过一会处理以及如何处理取决于中断的类型)。可以先把中断分为两种,一种是外部中断,一种是内部中断。
外部中断也叫硬件中断,由硬件向cpu发出中断信号,然后cpu停下来处理这个中断,此时cpu是知道是那个设备发出的中断的,有个中断号,然后根据这个中断号调用对应的中断驱动程序对这个中断完成处理,这样一看cpu就像一个后端一样,根据请求信息处理对应事件。
内部中断就是指cpu内部出现的中断,系统调用就是内部中断。
课程内容 当通上电以后,设备也是在运行的,cpu也是在运行的,两个可以说是在并行运行,既然是在并行运行,就需要处理两者之间的同步性问题,而中断就可以处理这个问题。
PCLI是cpu内部的一个模块,是对外部设备中断的管理者,
驱动程序分为上下两部分,下半部分是中断处理程序,上半部分在我看来是缓存区,比如uart设备的可以把接收或者发送的字符串放在上半部分,然后就可以完成了设备和cpu的解耦。
$ ls的工作过程,看的不是很懂,关于uart的部分。
后续,稍微理解了uart,他是一个用于辅助计算机和设备通信的芯片,当计算机向设备发送数据的时候,通过uart串口把字节转换成一位一位的,然后设备把一位一位的数据传递给计算机的时候,通过uart串口把一位一位的数据转化成字节流传递给计算机。
打印$的流程就是先把$放入到uart的一个寄存器中,然后产生一个中断,把储存的字符发送到另一个uart中,这个uart链接到了虚拟控制台。
发送ls时,首先键盘会把字符发送到与之链接的uart上,然后uart发送数据到另一个uart上,这个uart拿到数据后就会产生一个中断,告诉计算器键盘输出了字符。
当中断要被某一个cpu处理的时候,这个cpu对应寄存器的变化如下
中断有点难理解,课上的内容半懂不懂的,有时间看看源码再理解一下吧。
Lecture10 这节课的主要内容是锁
需要锁的主要原因就是cpu是多核的,每个核都可能有一个程序流,这些程序流可能访问同一个共享数据,内核中就有很多全局数据结构,当多个进程在不同核心上运行然后同时进入系统调用就可能发生同时访问共享数据的问题。总而言之就是解决并行性系统中访存共享数据的问题。
锁会序列化操作,即可以控制并行系统关于同一个共享数据的访问顺序,通一个时刻内,只有一个核可以访问共享数据段,当然,这势必会造成性能损失。
比如freelist就可能造成条件竞争。
在xv6中关于锁主要有两个函数调用acquire()和release(),第一个函数是获得锁,第二个函数是释放锁。
锁可以有粗粒度锁和细粒度锁
锁可以解决条件竞争的问题,但是也会带来自己的问题,也就是众所周知的死锁问题。
加锁这个过程必须是原子序列的,在xv6中,使用的是amoswap指令完成加锁,原理就是amoswap会对addr这个地址加锁,然后执行完后面三个后再解锁,最后判断r2的值来判断是否获得锁了。如果等于0就是获得锁,如果等于1就是没有获得锁,秒啊。
老师提到的一个解决死锁问题的办法是把所有锁进行一个排序,然后进程获得多个锁的时候就按照这个顺序来获取,这样确实可以避免比较典型的死锁问题。但是排序问题似乎也很麻烦,需要一个好的策略。
锁对性能肯定会造成损失,要想尽可能不造成损失,只能尽可能对把共享数据结构细化,然后锁就能尽可能的细粒度,性能就能损失的尽可能少,但是这是非常复杂的,系统越大越不好实现,老师给出的观点是先使用粗粒度的锁,然后看有没有条件竞争,再细化锁。
所有核心想要进行内存操作都会经过一个内存控制器,硬件锁就是利用此完成对特定地址加锁,让执行几步操作后对此解锁。
Lecture11 book-read 上下文切换
每个cpu都有自己的调度程序线程以及调度程序栈,其上下文保存在cpu->context中,当shell进程切换到cat进程的时候,首先在shell的内核线程中调用yield()函数
1 2 3 4 5 6 7 8 9 void yield (void ) struct proc *p = acquire(&p->lock); p->state = RUNNABLE; sched(); release(&p->lock); }
先把当前进程的状态位改成RUNNABLE,然后调用sched()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void sched (void ) int intena; struct proc *p = if (!holding(&p->lock)) panic("sched p->lock" ); if (mycpu()->noff != 1 ) panic("sched locks" ); if (p->state == RUNNING) panic("sched running" ); if (intr_get()) panic("sched interruptible" ); intena = mycpu()->intena; swtch(&p->context, &mycpu()->context); mycpu()->intena = intena; }
主要就是调用了swtch()函数来保存上下文并恢复调度线程上下文,执行调度线程。
swtch中主要就是sd和ld,当最后执行ret的时候就返回到了调度程序线程上下文了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 000000008000267a <swtch>: 8000267a: 00153023 sd ra,0(a0) 8000267e: 00253423 sd sp,8(a0) 80002682: e900 sd s0,16(a0) 80002684: ed04 sd s1,24(a0) 80002686: 03253023 sd s2,32(a0) 8000268a: 03353423 sd s3,40(a0) 8000268e: 03453823 sd s4,48(a0) 80002692: 03553c23 sd s5,56(a0) 80002696: 05653023 sd s6,64(a0) 8000269a: 05753423 sd s7,72(a0) 8000269e: 05853823 sd s8,80(a0) 800026a2: 05953c23 sd s9,88(a0) 800026a6: 07a53023 sd s10,96(a0) 800026aa: 07b53423 sd s11,104(a0) 800026ae: 0005b083 ld ra,0(a1) 800026b2: 0085b103 ld sp,8(a1) 800026b6: 6980 ld s0,16(a1) 800026b8: 6d84 ld s1,24(a1) 800026ba: 0205b903 ld s2,32(a1) 800026be: 0285b983 ld s3,40(a1) 800026c2: 0305ba03 ld s4,48(a1) 800026c6: 0385ba83 ld s5,56(a1) 800026ca: 0405bb03 ld s6,64(a1) 800026ce: 0485bb83 ld s7,72(a1) 800026d2: 0505bc03 ld s8,80(a1) 800026d6: 0585bc83 ld s9,88(a1) 800026da: 0605bd03 ld s10,96(a1) 800026de: 0685bd83 ld s11,104(a1) 800026e2: 8082 ret
这个是scheduler函数,切换上下文后,就会执行swtch的下一条语句了,比较饶的就是获得锁和释放锁应该是一个进程干的事情,但是在调度的时候并不是这样,首先在yield中获得锁,然后在scheduler释放锁,目的保护进程不被其他cpu调度。看似形不成一个闭环,但其实是可以的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 void scheduler (void ) struct proc *p ; struct cpu *c = c->proc = 0 ; for (;;){ intr_on(); int nproc = 0 ; for (p = proc; p < &proc[NPROC]; p++) { acquire(&p->lock); if (p->state != UNUSED) { nproc++; } if (p->state == RUNNABLE) { p->state = RUNNING; c->proc = p; swtch(&c->context, &p->context); c->proc = 0 ; } release(&p->lock); } if (nproc <= 2 ) { intr_on(); asm volatile ("wfi" ) } } }
xv6为每个cpu准备了一个struct cpu,这个结构体里就会记录着这个cpu当前运行的proc等等,所有的struct cpu保存在一个数组里,利用当前cpu的tp寄存器的值进行索引。
sleep/wakeup
生产者是一个线程,消费者是一个线程,两个线程之间得需要一个同步机制来协调,比如生产者生产一个产品,消费者才能消费一个
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 struct semaphore { struct spinlock lock ; int count; }; void V (struct semaphore* s) acquire(&s->lock); s->count += 1 ; release(&s->lock); } void P (struct semaphore* s) while (s->count == 0 ) ; acquire(&s->lock); s->count -= 1 ; release(&s->lock); }
这个代码没问题,但是对于消费者来说,如果生产者没有生产的话,那就得一直自旋,十分浪费cpu资源,当引进同步机制后
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void V (struct semaphore* s) acquire(&s->lock); s->count += 1 ; wakeup(s); release(&s->lock); } void P (struct semaphore* s) acquire(&s->lock); while (s->count == 0 ) sleep(s, &s->lock); s->count -= 1 ; release(&s->lock); }
这样即考虑了cpu资源还考虑了条件竞争。
pipe就是利用锁和sleep/wakeup实现的,exit/wait也是。
总而言之,锁这块原理不绕,但是使用起来好绕啊。
课程内容 主要讲解thread switch
终于知道了定时器中断是个什么董熊了,每个核心都有一个定时器,这个定时器周期性的发出一些中断,这些中断就是定时器中断,所以就算程序没有主动陷入内核,在定时器发生的时候还是会陷入,此时就可以记录程序运行时长和是否切换程序的工作了。
在发生计时器中断的时候,内核处理程序就可以让出cpu给调度器,然后调度器切换线程,在xv6中,让出靠的是yields()函数。
进程之间的切换并不是从这个进程的直接切换到另一个进程的,而是从这个进程的内核线程(线程1)中切换到另一个进程的内核线程(线程2)中,然后在线程2中再自然返回到对应进程中(进程2)。
Lecture13 这节课主要讲解了sleep和wakeup,这是一种常见的协调机制。
当sleep/wakeup不使用锁作为参数的话实现伪代码如上图,如果使用这种sleep/wakeup的话就会造成严重的lost wakeup问题,例子如下
uartwrite释放锁之后,中断线程就开始执行了,因为是多核心,所以就会造成一种局面,wakup比slepp提前执行,导致sleep的线程没有人去唤醒了。这就是lsot wakeup。
我以为处理办法是让释放锁和睡眠是原子的就好了,但是xv6并不是这样实现的,而是使用p->lock,这样也达到了效果。
老师对wait函数也进行了讲解,才明白过来其实子进程的资源回收并不是由子进程自己完成的,而是对自己状态进行标注为可以回收,然后父进程调用wait()的时候检查子进程然后回收。(当然不可能自己回收自己)。
Lecture14 这节课主要是文件系统的讲解
LAB Lab1: Xv6 and Unix utilities 这个实验主要是熟悉xv6的系统调用接口的。
sleep 1 2 3 4 5 6 7 8 9 10 11 #include "kernel/types.h" #include "user/user.h" int main (int argc,char *argv[]) if (argc!=2 ){ fprintf (2 ,"your parameter is not number\n" ); exit (1 ); } sleep(atoi(argv[1 ])); exit (0 ); }
pingpong 利用pipe完成父子进程之间双向通信,刚开始没理解透pipe,只用了一个管道,发现怎么都不对,看了别人的代码才恍然大雾,pipe只能完成单向通信,双向肯定得要两个管道啊,不过我错误那一版骗过了lab检查程序,乐
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include "kernel/types.h" #include "user/user.h" #define rd 0 #define wt 1 int main (int argc,char *argv[]) int p_to_child[2 ]; int p_to_parent[2 ]; char buf[10 ]; pipe(p_to_child); pipe(p_to_parent); int pid=fork(); if (pid<0 ){ fprintf (2 ,"fork fail\n" ); exit (1 ); } if (pid==0 ){ close(p_to_child[wt]); close(p_to_parent[rd]); int ret=read(p_to_child[rd],buf,1 ); if (ret<=0 ){ fprintf (2 ,"read fail\n" ); exit (1 ); } fprintf (1 ,"%d: received ping\n" ,getpid()); ret=write(p_to_parent[wt],"1" ,1 ); if (ret<=0 ){ fprintf (2 ,"write fail\n" ); exit (1 ); } close(p_to_child[rd]); close(p_to_parent[wt]); exit (0 ); }else { close(p_to_child[rd]); close(p_to_parent[wt]); int ret=write(p_to_child[wt],"1" ,1 ); if (ret<=0 ){ fprintf (2 ,"write fail\n" ); exit (1 ); } ret=read(p_to_parent[rd],buf,1 ); if (ret<=0 ){ fprintf (2 ,"read fail\n" ); exit (1 ); } fprintf (1 ,"%d: received pong\n" ,getpid()); close(p_to_child[wt]); close(p_to_parent[rd]); exit (0 ); } }
primes 这个程序还是比较麻烦的,要求利用fork和管道完成对素数的筛选,理论如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include "kernel/types.h" #include "user/user.h" #define rd 0 #define wt 1 int fun (int p_rd,int c_wt) int first_num=0 ; int temp=0 ; read(p_rd,&first_num,4 ); fprintf (1 ,"prime %d\n" ,first_num); int num; while (read(p_rd,&num,4 )){ if (num%first_num!=0 ){ temp++; write(c_wt,&num,4 ); } } return temp; } int main () int p[2 ]; int c[2 ]; int status; pipe(p); for (int i=2 ;i<=35 ;i++){ write(p[wt],&i,4 ); } while (1 ) { int pid=fork(); if (pid==0 ){ pipe(c); close(p[wt]); int ret=fun(p[rd],c[wt]); close(p[rd]); if (ret==0 ){ break ; } p[rd]=c[rd]; p[wt]=c[wt]; }else { if (p[wt]){ close(p[wt]); } if (p[rd]){ close(p[rd]); } wait(&status); if (status==1 ){ fprintf (2 ,"wait fail\n" ); exit (1 ); } exit (0 ); } } exit (0 ); }
find 这个调了我半个早上🤦♀️,首先是程序退出时报错,我试了半天才发现xv6系统的main函数只能以exit()退出,其次是测试程序老是过不去,多方调试后发现自己的一块逻辑写的有明显问题,呜呜呜这明明只是中等难度,代码能力还是太菜了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/fs.h" void find (char *file_path,char *res) struct stat st ; struct dirent de ; char buf[100 ]; memset (buf,0 ,sizeof (buf)); char *p; memmove(buf,file_path,strlen (file_path)); int fd=open(file_path,0 ); if (fd<0 ){ fprintf (2 ,"open fail\n" ); exit (1 ); } while (read(fd,&de,sizeof (de))==sizeof (de)){ if (de.inum==0 ){ break ; } if (!strcmp (de.name,"." )||!strcmp (de.name,".." )){ continue ; } p=buf+strlen (buf); memmove(p, de.name, DIRSIZ); if (stat(buf,&st)<0 ){ fprintf (2 ,"stat() fail filename :%s\n" ,buf); exit (1 ); } if (st.type==T_FILE){ if (!strcmp (de.name,res)){ fprintf (1 ,"%s\n" ,buf); } }else if (st.type==T_DIR) { p=buf+strlen (buf); *p='/' ; find(buf,res); } memset (buf,0 ,sizeof (buf)); memmove(buf,file_path,100 ); } close(fd); return ; } void main (int argc,char *argv[]) char buf[100 ]; char *p; memset (buf,0 ,sizeof (buf)); if (argc!=3 ){ fprintf (2 ,"parameter fail\n" ); exit (1 ); } memmove(buf,argv[1 ],DIRSIZ); p=buf+strlen (buf)-1 ; if (*p!='/' ){ p++; *p='/' ; } find(buf,argv[2 ]); exit (0 ); }
xargs 主要麻烦的点在对字符串的处理上,我看别人的博客利用了有限自动机,嘿嘿,不会这个高端的东西,我的解决办法是对得到的字符串进行标准化,然后就利于后面的字符串处理了(无脑做法属于)。还有我的代码能力真得弱,这点代码花了我两个小时。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/fs.h" int get_line_length (char *buf) int line_length=0 ; while (buf[line_length]!='\n' ){ line_length++; } return line_length; } int main (int argc,char *argv[]) char buf[100 ]={0 }; int cur=0 ; int line_num=0 ; int status; if (argc<2 ){ fprintf (2 ,"argv fail\n" ); exit (1 ); } int size=read(0 ,buf,100 ); char parm_buf[size+20 ]; memset (parm_buf,0 ,sizeof (parm_buf)); cur++; for (int i=0 ;i<size; i++,cur++){ if (buf[i]==' ' ){ continue ; } if (buf[i]=='\n' ){ cur++; parm_buf[cur]='\n' ; line_num++; cur++; continue ; } parm_buf[cur]=buf[i]; } if (buf[size-1 ]!='\n' ){ line_num++; } cur=0 ; for (int i=0 ;i<line_num;i++){ int add_parm_num=0 ; int temp_cur=cur; for (;parm_buf[temp_cur]!='\n' ;temp_cur++){ if (parm_buf[temp_cur]==0 &&parm_buf[temp_cur+1 ]!=0 &&parm_buf[temp_cur+1 ]!='\n' ){ add_parm_num++; } } char *parm[add_parm_num+argc]; memset (parm,0 ,sizeof (parm)); int parm_cur=0 ; for (int j=1 ;j<argc;j++,parm_cur++){ parm[parm_cur]=argv[j]; } for (;parm_buf[cur]!='\n' ;cur++){ if (parm_buf[cur]==0 &&parm_buf[cur+1 ]!=0 &&parm_buf[cur+1 ]!='\n' ){ parm[parm_cur]=&parm_buf[cur+1 ]; parm_cur++; } } cur++; int pid=fork(); if (pid==0 ){ exec(parm[0 ],parm); fprintf (2 ,"exec fail\n" ); exit (1 ); }else { wait(&status); if (status==1 ){ fprintf (2 ," wait fail\n" ); exit (1 ); } } } exit (0 ); }
最后lab得分 结语 在xv6操作系统上编程很奇妙也很有意思。
Lab2: system calls 这个实验主要是为了理解系统调用的工作流程,并为xv6增加一些新的系统调用。
book-read trap 有三种时间导致cpu搁置普通指令的执行,强制将控制权转移给处理该事件的特殊代码上,一种情况是系统调用使用ecall的时候,一种是异常,比如user/kernel指令做了一些非法的事情如除零,第三种是设备中断,这三种情况被统称为trap,xv6内核处理所有的trap.
risc-v陷入机制 risc-v架构的cpu都有一组控制寄存器,kernel通过向这些寄存器写入内容来使cpu处理trap
下面是重要的寄存器
stvec:内核在这里写入trap处理程序的地址,risc-v跳转到这里处理trap
sepc:当发生trap时,risc-v会保存原来pc的信息到sepc,sret(从陷阱返回)指令就会将sepc复制到pc,内核可以写入sepc来控制sret的去向。
scause:risc-v在这里防止描述trap原因的数字
sscratch:内核在这里放置一个值,这个值在trap处理程序一开始就会派上用场。
sstatus:其中的SIE位控制设备中断是否启动,SPP位指示trap是来自user-mode还是kernel-mode,并控制sret返回的模式
risc-v硬件对所有trap(除了计时器中断)执行以下操作
如果陷阱是设备中断,并且状态SIE 位被清空,则不执行以下任何操作。
清除SIE 以禁用中断。
将pc复制到sepc。
将当前模式(用户或管理)保存在状态的SPP 位中。
设置scause以反映产生陷阱的原因。
将模式设置为管理模式。
将stvec复制到pc。
在新的pc上开始执行。
可见cpu硬件只会执行这些操作,当控制权给到内核的时候,得要内核自己完成对内核页表的切换,对内核栈的切换,然后进入对trap真正处理的函数上,对除了pc以外所有寄存器的保存。
从用户空间陷入
总体分为四步调用,uservec,usertrap,usertrapret和userret。
uservec
uservec代码处于kernel/trampoline.S中,一猜就是用汇编写的,因为控制单位到了寄存器量级,但是是risc-v捏,看不太懂。如上面所说,kernel-mode得完成那些操作才可以进入对trap真正处理的函数上(usertrap),而这些操作都被放置在uservec中,即刚开始的stvec指向了uservec,但是刚进入kernel-mode的时候satp并没有指向kernel-page,而是在user-page中,要想执行uservec则必须在用户页表中也映射上,在uservec中会切换satp以指向内核页表,所以为了在切换后继续执行指令,uservec必须在内核页表和用户页表中映射相同的地址。
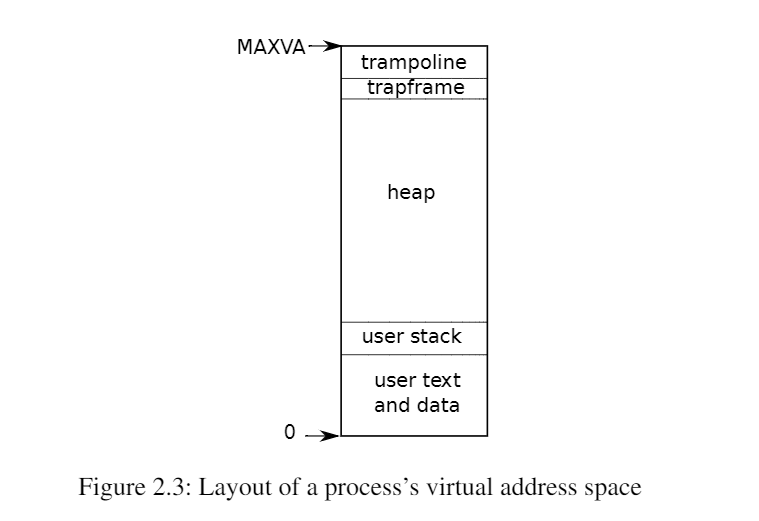
为此xv6专门设置了一个页面放置uservec代码,然后把这个页面映射到内核页表和所有的用户页表中,且虚拟地址全部相同,这个虚拟地址就是上图的trampoline,在user-mode时stvec就指向了trampoline即userevc。
到这里我觉得十分合理,可能x86也是这样干的,当userevc启动的时候,所有的32个寄存器都保存着原来中断代码的值,不能够随意更改,但userevc需要能够使用一些寄存器才能完成他的功能,risc-v的sscratch就发挥了作用,userevc开始的时候通过指令csrrw交换了a0和sscratch的内容,此时a0寄存器的值就被保存了,uservec就可以使用a0寄存器了。
具体该怎么保存所有的寄存器的值,就牵扯到了另一个机制陷阱帧,如上图所示,陷阱帧就是trapframe,该帧有保存用户所有的寄存器的空间。此时satp还是指向了用户页表,所以要使用这个陷阱帧还得把他映射到用户页表中,sscratch就指向了这个陷阱帧,执行完csrrw后a0寄存器就指向了陷阱帧,然后uservec就利用a0把所有用户寄存器保存在陷阱帧,陷阱帧中还包含了指向当前进程内核栈的指针,当前cpu的hartid,usertrap的地址以及内核页表的地址,uservec就取得这些值,将satp切换到内核页表,并调用usertrap。
usertrap
下面是xv6 usertrap代码
代码比较清晰,首先会检查上一个模式是什么,然后设置stvec,因为此时cpu已经处于内核态了,当发生trap时得执行内核的kernelvec而不是suervec,所以会把stvec指向kernelvec,然后保存了sepc到p->trapframe->sepc中防止被覆盖,然后判断trap的类型,如果是系统调用syscall()会处理,如果是设备中断,devintr会处理他,否则就是一个异常,就设置p->killed=1,代表会被杀死,最后内核检查进程是否应该被杀死或者因为时钟中断让出cpu,最后调用usertrapret,流程比起uservec好理解多了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 void usertrap (void ) int which_dev = 0 ; if ((r_sstatus() & SSTATUS_SPP) != 0 ) panic("usertrap: not from user mode" ); w_stvec((uint64)kernelvec); struct proc *p = p->trapframe->epc = r_sepc(); if (r_scause() == 8 ){ if (p->killed) exit (-1 ); p->trapframe->epc += 4 ; intr_on(); syscall(); } else if ((which_dev = devintr()) != 0 ){ } else { printf ("usertrap(): unexpected scause %p pid=%d\n" , r_scause(), p->pid); printf (" sepc=%p stval=%p\n" , r_sepc(), r_stval()); p->killed = 1 ; } if (p->killed) exit (-1 ); if (which_dev == 2 ) yield(); usertrapret(); }
usertrapret
首先是获得进程的proc结构体,然后是intr_off设置了sstatus的sie位,然后是设置了stvec,因为要返回用户态了,所以trap处理程序变成了uservec,然后是在陷阱帧中记录内核页表地址,sp地址,usertrap地址,以及hartid。然后是设置sstatus的ssp位,把上一个模式设置为user-mode,然后是设置sepc得到用户态页表地址,然后又跳回trampoline中执行userret,至于为什么要把userret函数放置在trampoline中,是因为userret中会切换页表。要想切换完页表还能继续执行userret只能把他放在trampoline中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 void usertrapret (void ) struct proc *p = intr_off(); w_stvec(TRAMPOLINE + (uservec - trampoline)); p->trapframe->kernel_satp = r_satp(); p->trapframe->kernel_sp = p->kstack + PGSIZE; p->trapframe->kernel_trap = (uint64)usertrap; p->trapframe->kernel_hartid = r_tp(); unsigned long x = r_sstatus(); x &= ~SSTATUS_SPP; x |= SSTATUS_SPIE; w_sstatus(x); w_sepc(p->trapframe->epc); uint64 satp = MAKE_SATP(p->pagetable); uint64 fn = TRAMPOLINE + (userret - trampoline); ((void (*)(uint64,uint64))fn)(TRAPFRAME, satp); }
userret
a1保存的是用户态页表地址,a0保存的是trampoline地址,首先切换页表,然后从陷阱帧中恢复用户寄存器,最后调用sret完成对用户态的切换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 .globl userret userret: # userret(TRAPFRAME, pagetable) # switch from kernel to user. # usertrapret() calls here. # a0: TRAPFRAME, in user page table. # a1: user page table, for satp. # switch to the user page table. csrw satp, a1 sfence.vma zero, zero # put the saved user a0 in sscratch, so we # can swap it with our a0 (TRAPFRAME) in the last step. ld t0, 112(a0) csrw sscratch, t0 # restore all but a0 from TRAPFRAME ld ra, 40(a0) ld sp, 48(a0) ld gp, 56(a0) ld tp, 64(a0) ld t0, 72(a0) ld t1, 80(a0) ld t2, 88(a0) ld s0, 96(a0) ld s1, 104(a0) ld a1, 120(a0) ld a2, 128(a0) ld a3, 136(a0) ld a4, 144(a0) ld a5, 152(a0) ld a6, 160(a0) ld a7, 168(a0) ld s2, 176(a0) ld s3, 184(a0) ld s4, 192(a0) ld s5, 200(a0) ld s6, 208(a0) ld s7, 216(a0) ld s8, 224(a0) ld s9, 232(a0) ld s10, 240(a0) ld s11, 248(a0) ld t3, 256(a0) ld t4, 264(a0) ld t5, 272(a0) ld t6, 280(a0) # restore user a0, and save TRAPFRAME in sscratch csrrw a0, sscratch, a0 # return to user mode and user pc. # usertrapret() set up sstatus and sepc. sret
借助从用户态的陷入终于理清了xv6的用户态和内核态的转换了,受益匪浅。
调用系统调用
syscall代码如下,代码简略清晰,就以exec调用位例子,两个参数分别存放在a0,和a1中,然后把系统调用号放在a7中,系统调用号就是syscall[]的下标,寻找到的值就是该系统调用的处理函数,exec系统调用最后就会调用sys_exec。此时会有个疑问,系统调用都是有参数的,为什么最后的p->trapframe->a0 = syscalls[num]();没有呢,我大概看了sys_exec的代码,发现他是直接从陷阱帧中取寄存器值的,而不是传参。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 static uint64 (*syscalls[]) (void ) [SYS_fork] sys_fork, [SYS_exit] sys_exit, [SYS_wait] sys_wait, [SYS_pipe] sys_pipe, [SYS_read] sys_read, [SYS_kill] sys_kill, [SYS_exec] sys_exec, [SYS_fstat] sys_fstat, [SYS_chdir] sys_chdir, [SYS_dup] sys_dup, [SYS_getpid] sys_getpid, [SYS_sbrk] sys_sbrk, [SYS_sleep] sys_sleep, [SYS_uptime] sys_uptime, [SYS_open] sys_open, [SYS_write] sys_write, [SYS_mknod] sys_mknod, [SYS_unlink] sys_unlink, [SYS_link] sys_link, [SYS_mkdir] sys_mkdir, [SYS_close] sys_close, }; void syscall (void ) int num; struct proc *p = num = p->trapframe->a7; if (num > 0 && num < NELEM(syscalls) && syscalls[num]) { p->trapframe->a0 = syscalls[num](); } else { printf ("%d %s: unknown sys call %d\n" , p->pid, p->name, num); p->trapframe->a0 = -1 ; } }
系统调用参数 好家伙,我刚有这个疑问,书的下一节就解释这个问题,牛啊。
系统提供三个函数artint,artaddr,artfd从陷阱帧中检索第n个系统调用参数并且以整数,指针,或者文件描述符的形式保存,他们都调用argraw来检索相应的保存的用户寄存器。比如argstr函数
1 2 3 4 5 6 7 8 9 10 11 12 argstr(int n, char *buf, int max) { uint64 addr; if (argaddr(n, &addr) < 0 ) return -1 ; return fetchstr(addr, buf, max); } argaddr(int n, uint64 *ip) { *ip = argraw(n); return 0 ; }
内核要想获得一个整数还行,但是要想获得用户态的某一个字符串或者某一段内存的值就不好办了,因为此时处于内核态,页表是内核页表,并不能访问用户态的内存,可以看看xv6是如何完成的。
copyinstr函数就是完成在内核态从用户态到内核态拷贝数据的函数,传入的参数有进程的陷阱帧,内核接收地址dst和用户态地址srcva以及拷贝量max。我简述一下原理,就是利用传进来的用户态虚拟地址srcva和进程的陷阱帧完成对这个虚拟地址所映射的物理地址pa0的查询,查询过程就是利用陷阱帧记录的用户态页表,然后通过这个虚拟地址找到对应物理地址返回,在内核态中,由于内核将所有物理RAM地址映射到同一个内核虚拟地址,copyinstr可以直接将字符串字节从pa0复制到dst(这段其实不是很理解,我不确定这个pa0到底是不是物理地址,如果是的话copyinstr直接使用物理地址进行copy*dst = *p,那唯一的解释就是映射是直接映射,即虚拟地址和物理地址是一一对应的才可以)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 copyinstr(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max) { uint64 n, va0, pa0; int got_null = 0 ; while (got_null == 0 && max > 0 ){ va0 = PGROUNDDOWN(srcva); pa0 = walkaddr(pagetable, va0); if (pa0 == 0 ) return -1 ; n = PGSIZE - (srcva - va0); if (n > max) n = max; char *p = (char *) (pa0 + (srcva - va0)); while (n > 0 ){ if (*p == '\0' ){ *dst = '\0' ; got_null = 1 ; break ; } else { *dst = *p; } --n; --max; p++; dst++; } srcva = va0 + PGSIZE; } if (got_null){ return 0 ; } else { return -1 ; } }
通过在qemu下打印页表发现似乎就是这样的,映射了个寂寞🤦♀️,在linux系统中内核好歹是线性映射所有物理区域,xv6直接一对一了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 vaddr paddr size attr ---------------- ---------------- ---------------- ------- 0000000002000000 0000000002000000 0000000000010000 rw----- 000000000c000000 000000000c000000 0000000000001000 rw---ad 000000000c001000 000000000c001000 0000000000001000 rw----- 000000000c002000 000000000c002000 0000000000001000 rw---ad 000000000c003000 000000000c003000 00000000001fe000 rw----- 000000000c201000 000000000c201000 0000000000001000 rw---ad 000000000c202000 000000000c202000 0000000000001000 rw----- 000000000c203000 000000000c203000 0000000000001000 rw---ad 000000000c204000 000000000c204000 0000000000001000 rw----- 000000000c205000 000000000c205000 0000000000001000 rw---ad 000000000c206000 000000000c206000 00000000001fa000 rw----- 0000000010000000 0000000010000000 0000000000002000 rw---ad 0000000080000000 0000000080000000 0000000000007000 r-x--a- 0000000080007000 0000000080007000 0000000000001000 r-x---- 0000000080008000 0000000080008000 0000000000005000 rw---ad 000000008000d000 000000008000d000 0000000000004000 rw----- 0000000080011000 0000000080011000 0000000000011000 rw---ad 0000000080022000 0000000080022000 0000000000001000 rw----- 0000000080023000 0000000080023000 0000000000003000 rw---ad 0000000080026000 0000000080026000 0000000007f35000 rw----- 0000000087f5b000 0000000087f5b000 000000000005d000 rw---ad 0000000087fb8000 0000000087fb8000 0000000000001000 rw---a- 0000000087fb9000 0000000087fb9000 0000000000046000 rw----- 0000000087fff000 0000000087fff000 0000000000001000 rw---a- 0000003ffff7f000 0000000087f77000 000000000003e000 rw----- 0000003fffffb000 0000000087fb5000 0000000000002000 rw---ad 0000003ffffff000 0000000080007000 0000000000001000 r-x--a-
从内核态陷入 书中涉及到了计数器中断的处理办法,由于我不是很熟悉计数器中断,所以暂且不讨论这种情况,在第七章中会系统的学到。我只讨论一般情况下的内核陷入。
内核发生陷入的话只有两种情况,一是设备中断,二是内核异常,此时是处于内核态的,stvec就指向了kernelvec,然后处理trap也是在内核态,所以不需要切换页表了。处理流程主要是两个函数:kernelvec->kerneltrap->kernelvec
kernelvec
意料之中又是risc-v汇编捏,但是大概是能看懂的,kernelvec首先得把所有的寄存器存放到当前内核栈的栈上,所以首先addi sp.sp,-256就是sp=sp+(-256),先提升栈的容量。然后把寄存器放在这256容量的栈里,sd ra,0(sp)等于*[sp+0]=ra这样的形式存储,至于为什么要存储所有的寄存器,是因为在调用kerneltrap的时候,会因为时钟中断而让出cpu导致丢失寄存器信息,所以得记录一下,记录完就是调用kerneltrap了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 # interrupts and exceptions while in supervisor # mode come here. # # push all registers, call kerneltrap(), restore, return. # .globl kerneltrap .globl kernelvec .align 4 kernelvec: // make room to save registers. addi sp, sp, -256 // save the registers. sd ra, 0(sp) sd sp, 8(sp) sd gp, 16(sp) sd tp, 24(sp) sd t0, 32(sp) sd t1, 40(sp) sd t2, 48(sp) sd s0, 56(sp) sd s1, 64(sp) sd a0, 72(sp) sd a1, 80(sp) sd a2, 88(sp) sd a3, 96(sp) sd a4, 104(sp) sd a5, 112(sp) sd a6, 120(sp) sd a7, 128(sp) sd s2, 136(sp) sd s3, 144(sp) sd s4, 152(sp) sd s5, 160(sp) sd s6, 168(sp) sd s7, 176(sp) sd s8, 184(sp) sd s9, 192(sp) sd s10, 200(sp) sd s11, 208(sp) sd t3, 216(sp) sd t4, 224(sp) sd t5, 232(sp) sd t6, 240(sp) // call the C trap handler in trap.c call kerneltrap // restore registers. ld ra, 0(sp) ld sp, 8(sp) ld gp, 16(sp) // not this, in case we moved CPUs: ld tp, 24(sp) ld t0, 32(sp) ld t1, 40(sp) ld t2, 48(sp) ld s0, 56(sp) ld s1, 64(sp) ld a0, 72(sp) ld a1, 80(sp) ld a2, 88(sp) ld a3, 96(sp) ld a4, 104(sp) ld a5, 112(sp) ld a6, 120(sp) ld a7, 128(sp) ld s2, 136(sp) ld s3, 144(sp) ld s4, 152(sp) ld s5, 160(sp) ld s6, 168(sp) ld s7, 176(sp) ld s8, 184(sp) ld s9, 192(sp) ld s10, 200(sp) ld s11, 208(sp) ld t3, 216(sp) ld t4, 224(sp) ld t5, 232(sp) ld t6, 240(sp) addi sp, sp, 256 // return to whatever we were doing in the kernel. sret
kerneltrap
首先是储存sepc和sstatus两个寄存器,因为如果有时钟中断而调用yield()函数的时候会破坏他们,要使破坏了他们trap返回的时候就会出问题,保存完后真正处理trap,处理完之后恢复sepc和sstatus,然后返回到函数kernelvec中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void kerneltrap () int which_dev = 0 ; uint64 sepc = r_sepc(); uint64 sstatus = r_sstatus(); uint64 scause = r_scause(); if ((sstatus & SSTATUS_SPP) == 0 ) panic("kerneltrap: not from supervisor mode" ); if (intr_get() != 0 ) panic("kerneltrap: interrupts enabled" ); if ((which_dev = devintr()) == 0 ){ printf ("scause %p\n" , scause); printf ("sepc=%p stval=%p\n" , r_sepc(), r_stval()); panic("kerneltrap" ); } if (which_dev == 2 && myproc() != 0 && myproc()->state == RUNNING) yield(); w_sepc(sepc); w_sstatus(sstatus); }
返回到kernelvec中就会简单了,就利用栈信息恢复通用寄存器,然后addi sp, sp, 256后sret结束内核陷入。
总而言之比用户态陷入要简单很多了。
页面错误异常 这个暂时不看,涉及到了第三章的知识,暂时还没有学习到。
System call tracing 就是增加一个系统调用追踪的功能,可以先利用这个系统调用设置自己想要追踪的系统调用,然后这个程序以及子程序在调用这个系统调用的时候都会打印相应数据。
编程不是难点,难点可能是理清楚系统调用的原理以及对应的几个c文件就好了,只要阅读过书籍的第四章问题就不大的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void trace_printf_sysname () struct proc *p = int mask=p->trace_num; int sys_num=p->trapframe->a7; if (mask&(1 <<sys_num)){ printf ("%d: syscall %s -> %d\n" ,p->pid,syscall_name[sys_num],p->trapframe->a0); } } uint64 sys_trace (void ) int mask; struct proc *p = if (argint(0 ,&mask)<0 ){ return -1 ; } p->trace_num=mask; return 0 ; }
Sysinfo 这个系统调用个就比较麻烦了,首先得把结构体从struct sysinfo从内核态拷贝回用户空间,然后得在内核获得空闲内存量,然后还得获得stat不为UNUSED的进程数。都没怎么听过,得阅读源码慢慢搞清楚。
从内核态拷贝数据使用的是copyout函数,之前分析过copyin函数,原理都是差不多的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int copyout (pagetable_t pagetable, uint64 dstva, char *src, uint64 len) uint64 n, va0, pa0; while (len > 0 ){ va0 = PGROUNDDOWN(dstva); pa0 = walkaddr(pagetable, va0); if (pa0 == 0 ) return -1 ; n = PGSIZE - (dstva - va0); if (n > len) n = len; memmove((void *)(pa0 + (dstva - va0)), src, n); len -= n; src += n; dstva = va0 + PGSIZE; } return 0 ; }
获得内存空闲字节课以通过阅读kmalloc.c源码很好的解决,在xv6系统中定义了两个结构体来管理空闲页面其中通过struct run组成一个单向链表来链接所有的空闲链表,然后通过struct kmem.freelist指向这个链表的头结点,所以只需要遍历这个链表就可以所有空闲页面了。
1 2 3 4 5 6 7 8 struct run { struct run *next ; }; struct { struct spinlock lock ; struct run *freelist ; } kmem;
在struct proc中有一个字段struct proc *parent可以通过遍历这个字段完成对进程数的统计,这种统计方式肯定有问题,因为一个进程可以有多个子进程,这个办法每一层进程只能遍历一个,与其说统计有多少个进程,不如说统计有多少层进程,当然这也是struct proc的设计问题,只能这样干。
代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 uint64 sys_sysinfo (void ) struct proc *p = struct sysinfo info ; uint64 user_info; if (argaddr(0 ,&user_info)<0 ){ printf ("sysinfo addr get fail\n" ); } info.freemem=countfree(); info.nproc=get_proc_num(); if (copyout(p->pagetable,user_info,(char *)&info,sizeof (info))<0 ){ return -1 ; } return 0 ; } int countfree (void ) int n=0 ; struct run *r ; r=kmem.freelist; while (r){ n=n+4096 ; r=r->next; } return n; } int get_proc_num () struct proc *p = int num=0 ; while (p->parent){ if (p->state!=UNUSED){ num++; } p=p->parent; } return num; }
得分 结语 对系统调用理解的更深了吧,之前只知道大概思想,现在也知道了如何实现的,也对xv6的用户态和内核态的切换更加熟悉,也更加了解了xv6的源代码。
Lab3: page tables code-read 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 walk(pagetable_t pagetable, uint64 va, int alloc) { if (va >= MAXVA) panic("walk" ); for (int level = 2 ; level > 0 ; level--) { pte_t *pte = &pagetable[PX(level, va)]; if (*pte & PTE_V) { pagetable = (pagetable_t )PTE2PA(*pte); } else { if (!alloc || (pagetable = (pde_t *)kalloc()) == 0 ) return 0 ; memset (pagetable, 0 , PGSIZE); *pte = PA2PTE(pagetable) | PTE_V; } } return &pagetable[PX(0 , va)]; } int mappages (pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm) uint64 a, last; pte_t *pte; a = PGROUNDDOWN(va); last = PGROUNDDOWN(va + size - 1 ); for (;;){ if ((pte = walk(pagetable, a, 1 )) == 0 ) return -1 ; if (*pte & PTE_V) panic("remap" ); *pte = PA2PTE(pa) | perm | PTE_V; if (a == last) break ; a += PGSIZE; pa += PGSIZE; } return 0 ; } void kvmmap (uint64 va, uint64 pa, uint64 sz, int perm) if (mappages(kernel_pagetable, va, sz, pa, perm) != 0 ) panic("kvmmap" ); } void kvminit () kernel_pagetable = (pagetable_t ) kalloc(); memset (kernel_pagetable, 0 , PGSIZE); kvmmap(UART0, UART0, PGSIZE, PTE_R | PTE_W); kvmmap(VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W); kvmmap(CLINT, CLINT, 0x10000 , PTE_R | PTE_W); kvmmap(PLIC, PLIC, 0x400000 , PTE_R | PTE_W); kvmmap(KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X); kvmmap((uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W); kvmmap(TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X); }
读完代码后感觉内核并不是直接运行在物理内存上的,他也遵循虚拟内存,所以要控制整个物理内存的话就需要一段虚拟地址对整个物理内存进行映射,通过这段虚拟地址控制整个物理内存。
book-read 创建一个地址空间 在内核启动的时候,首先会调用main函数,main会调用上述介绍的kvminit来初始化内核页表,kvminit已经分析过了,接着看kvminithart
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 void main () if (cpuid() == 0 ){ consoleinit(); #if defined(LAB_PGTBL) || defined(LAB_LOCK) statsinit(); #endif printfinit(); printf ("\n" ); printf ("xv6 kernel is booting\n" ); printf ("\n" ); kinit(); kvminit(); kvminithart(); procinit(); trapinit(); trapinithart(); plicinit(); plicinithart(); binit(); iinit(); fileinit(); virtio_disk_init(); #ifdef LAB_NET pci_init(); sockinit(); #endif userinit(); __sync_synchronize(); started = 1 ; } else { while (started == 0 ) ; __sync_synchronize(); printf ("hart %d starting\n" , cpuid()); kvminithart(); trapinithart(); plicinithart(); } scheduler(); }
上一个函数设置好内核页表之后,这个函数就是让satp寄存器指向这个页表,到这里cpu才开启了虚拟内存,之前全部都是直接在物理内存上干的。
当开始虚拟地址之前,pc寄存器记录着下一个指令的物理地址,当开启了之后,pc寄存器就记录着下一个指令的虚拟地址,就需要翻译了,但由于xv6操作系统是采用直接映射的,所以开了和没开差不多✌
1 2 3 4 5 kvminithart() { w_satp(MAKE_SATP(kernel_pagetable)); sfence_vma(); }
然后又调用procinit函数,这个函数就是遍历所有的进程的proc结构体,然后利用kalloc申请一个页表,不过我稍微有问题的就是kalloc返回的是虚拟地址,虽说是直接映射,但是他直接默认成物理地址了,还是不太严谨,容易产生误导。然后利用KSTACK计算出这个进程的内核栈的虚拟地址,然后调用kvmmap进行映射。
退出for循环之后还得调用kvminithart函数,因为已经更改了页表,就必须刷新TLB,不然可能会映射出错,而这个函数中的sfence_vma函数调用会执行sfence.vma指令,这个指令就会刷新TLB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void procinit (void ) struct proc *p ; initlock(&pid_lock, "nextpid" ); for (p = proc; p < &proc[NPROC]; p++) { initlock(&p->lock, "proc" ); char *pa = kalloc(); if (pa == 0 ) panic("kalloc" ); uint64 va = KSTACK((int ) (p - proc)); kvmmap(va, (uint64)pa, PGSIZE, PTE_R | PTE_W); p->kstack = va; } kvminithart(); }
物理内存分配
分配器的代码主要集中在kalloc.c文件中,之前已经分析过了,在main函数中会调用kinit函数来初始化分配器,看着还是比较清楚地,就是把地址空间中从内核末尾到PHYSTOP的地址按每一页进行free,然后放到freelist中了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void kinit () initlock(&kmem.lock, "kmem" ); freerange(end, (void *)PHYSTOP); } void freerange (void *pa_start, void *pa_end) char *p; p = (char *)PGROUNDUP((uint64)pa_start); for (; p + PGSIZE <= (char *)pa_end; p += PGSIZE) kfree(p); }
exec代码分析 exec函数是创建用户地址空间时使用的系统调用,在代码中侧重关注对elf文件的解析以及如何创建进程的地址空间。
函数首先经过一系列处理把elf头读到elf变量中,然后对魔数进行判断,然后调用proc_pagetable(p)返回个一个新的页表,这个页表中已经映射了跳板和陷阱帧。然后就是利用一个for循环把程序装载到内存中并配置页表,其中uvmalloc函数就是申请内存页然后配置页表,然后loadseg函数就是把二进制程序加载到申请的内存页中,大概是这样,但是具体如何加载elf每个段的还是看不太懂。
之后就是设置进程的栈,然后初始化了栈,在里面放了argc和argv,最后设置了陷阱帧的一些东西和页表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 int exec (char *path, char **argv) char *s, *last; int i, off; uint64 argc, sz = 0 , sp, ustack[MAXARG+1 ], stackbase; struct elfhdr elf ; struct inode *ip ; struct proghdr ph ; pagetable_t pagetable = 0 , oldpagetable; struct proc *p = begin_op(); if ((ip = namei(path)) == 0 ){ end_op(); return -1 ; } ilock(ip); if (readi(ip, 0 , (uint64)&elf, 0 , sizeof (elf)) != sizeof (elf)) goto bad; if (elf.magic != ELF_MAGIC) goto bad; if ((pagetable = proc_pagetable(p)) == 0 ) goto bad; for (i=0 , off=elf.phoff; i<elf.phnum; i++, off+=sizeof (ph)){ if (readi(ip, 0 , (uint64)&ph, off, sizeof (ph)) != sizeof (ph)) goto bad; if (ph.type != ELF_PROG_LOAD) continue ; if (ph.memsz < ph.filesz) goto bad; if (ph.vaddr + ph.memsz < ph.vaddr) goto bad; uint64 sz1; if ((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz)) == 0 ) goto bad; sz = sz1; if (ph.vaddr % PGSIZE != 0 ) goto bad; if (loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0 ) goto bad; } iunlockput(ip); end_op(); ip = 0 ; p = myproc(); uint64 oldsz = p->sz; sz = PGROUNDUP(sz); uint64 sz1; if ((sz1 = uvmalloc(pagetable, sz, sz + 2 *PGSIZE)) == 0 ) goto bad; sz = sz1; uvmclear(pagetable, sz-2 *PGSIZE); sp = sz; stackbase = sp - PGSIZE; for (argc = 0 ; argv[argc]; argc++) { if (argc >= MAXARG) goto bad; sp -= strlen (argv[argc]) + 1 ; sp -= sp % 16 ; if (sp < stackbase) goto bad; if (copyout(pagetable, sp, argv[argc], strlen (argv[argc]) + 1 ) < 0 ) goto bad; ustack[argc] = sp; } ustack[argc] = 0 ; sp -= (argc+1 ) * sizeof (uint64); sp -= sp % 16 ; if (sp < stackbase) goto bad; if (copyout(pagetable, sp, (char *)ustack, (argc+1 )*sizeof (uint64)) < 0 ) goto bad; p->trapframe->a1 = sp; for (last=s=path; *s; s++) if (*s == '/' ) last = s+1 ; safestrcpy(p->name, last, sizeof (p->name)); oldpagetable = p->pagetable; p->pagetable = pagetable; p->sz = sz; p->trapframe->epc = elf.entry; p->trapframe->sp = sp; proc_freepagetable(oldpagetable, oldsz); return argc; bad: if (pagetable) proc_freepagetable(pagetable, sz); if (ip){ iunlockput(ip); end_op(); } return -1 ; }
Print a page table 打印页表,写的比较脑瘫
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void _vmprint(pagetable_t pagetable,int level){ for (int i=0 ;i<512 ;i++){ pte_t pte=pagetable[i]; if (!(pte&PTE_V)){ continue ; } if (level==1 ){ printf (".." ); }else if (level==2 ){ printf (".. .." ); }else if (level==3 ){ printf (".. .. .." ); } printf ("%d: %p pa %p\n" ,i,pte,PTE2PA(pte)); if ((pte&(PTE_X|PTE_W|PTE_R))==0 ){ uint64 child=PTE2PA(pte); _vmprint((pagetable_t )child,level+1 ); } } } void vmprint (pagetable_t pagetable) printf ("page table %p\n" ,pagetable); _vmprint(pagetable,1 ); }
A kernel page table per process 给每个进程实现一个内核页表的副本,只要理清思路就不难,然后代码实现仿照内核已有的函数写就行,我主要是卡在了scheduler()函数上,正确函数调用顺序如下,但是我刚开始吧uvminithart写在了swtch函数的下面,目前并不清楚这个函数是干啥的,但是按照这样写就没问题
1 2 3 4 5 uvminithart(p->kernelpage); swtch(&c->context, &p->context); kvminithart();
主要代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void proc_kernelpage_free (pagetable_t kernelpage) for (int i=0 ;i<512 ;i++){ pte_t pte=kernelpage[i]; if (!(pte&PTE_V)){ continue ; } if ((pte&(PTE_W|PTE_R|PTE_X))==0 ){ uint64 child=PTE2PA(pte); proc_kernelpage_free((pagetable_t )child); } kernelpage[i]=0 ; } kfree((void *)kernelpage); } void uvmmap (pagetable_t kernelpage,uint64 va, uint64 pa, uint64 sz, int perm) if (mappages(kernelpage,va,sz,pa,perm)!=0 ){ panic("uvmmap" ); } } pagetable_t proc_kvminit () pagetable_t kernlepage=(pagetable_t ) kalloc(); memset (kernlepage,0 ,PGSIZE); uvmmap(kernlepage,UART0, UART0, PGSIZE, PTE_R | PTE_W); uvmmap(kernlepage,VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W); uvmmap(kernlepage,CLINT, CLINT, 0x10000 , PTE_R | PTE_W); uvmmap(kernlepage,PLIC, PLIC, 0x400000 , PTE_R | PTE_W); uvmmap(kernlepage,KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X); uvmmap(kernlepage,(uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W); uvmmap(kernlepage,TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X); return kernlepage; }
Simplify copyin/copyinstr 代码太多了,把握的不是很好,加上没有善于利用git,导致我第二个实验做完没有开保存到工作区,最后实验三改着改着就改不回来了,我刚开始的思路就是用户页表映射的时候内核页表也跟着映射吗,但是最后是失败的,因为fork完后调用exec会导致对内核页表的重新映射而导致出错,进而程序崩溃,后来看了别人的思路,就是不利用内核提供的函数,而是自己写一个函数,来复制页表,这样确实会好很多,哎。猪鼻了这下。只能从头开始写这个实验了。
整了四五天还是疯狂报错。我吐了,照着写代码都不行,这个实验只能暂时搁浅了,后面有时间再整吧。
Lab4: traps RISC-V assembly 任务就是读懂这段汇编,但是之间没有认真接触过risc-v指令集,所以还是有些小困难,为了彻底搞懂,就从main处一行一行看吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 int g(int x) { 0: 1141 addi sp,sp,-16 2: e422 sd s0,8(sp) 4: 0800 addi s0,sp,16 return x+3; } 6: 250d addiw a0,a0,3 8: 6422 ld s0,8(sp) a: 0141 addi sp,sp,16 c: 8082 ret 000000000000000e <f>: int f(int x) { e: 1141 addi sp,sp,-16 10: e422 sd s0,8(sp) 12: 0800 addi s0,sp,16 return g(x); } 14: 250d addiw a0,a0,3 16: 6422 ld s0,8(sp) 18: 0141 addi sp,sp,16 1a: 8082 ret 000000000000001c <main>: void main(void) { 1c: 1141 addi sp,sp,-16 #sp=sp+0x10 1e: e406 sd ra,8(sp) # *(sp+0x8)=ra 20: e022 sd s0,0(sp) #*(sp+0x0)=s0,s0相当于x86中的rbp我感觉,就是记录栈顶的值,即帧指针 22: 0800 addi s0,sp,16 #s0=sp+0x10,就是记录这个函数的帧指针 printf("%d %d\n", f(8)+1, 13); 24: 4635 li a2,13 #a2=13 26: 45b1 li a1,12 #a1=12 28: 00000517 auipc a0,0x0 #a0=(0x0<<12)+pc #auipc rd, imm # 将 20 位的立即数左移12位,低 12 位补零,将得到的 32 位数与 pc 的值相加,最后写回寄存器 rd 中 2c: 7a850513 addi a0,a0,1960 # 7d0 <malloc+0xea> #a0=a0+1960,此时a0就存储着字符串的地址了。,感觉就是相对于pc的寻址,只不过拆成了两步 30: 00000097 auipc ra,0x0 #ra=(0x0<<12)+pc 34: 5f8080e7 jalr 1528(ra) # 628 <printf> #pc=ra+1528, ra+=8,此时就跳转到了printf函数 exit(0); 38: 4501 li a0,0 #a0=0 3a: 00000097 auipc ra,0x0 #ra=pc 3e: 276080e7 jalr 630(ra) # 2b0 <exit> #pc=ra+630,ra+=8
一行一行分析下来发现其实并没有调用f和g函数,被编译器优化掉了,直接把12赋值给a1,13赋值给a2了。
问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 哪些寄存器保存函数的参数?例如,在main对printf的调用中,哪个寄存器保存13? a2 main的汇编代码中对函数f的调用在哪里?对g的调用在哪里(提示:编译器可能会将函数内联) 并没有对f和g函数进行调用 printf函数位于哪个地址? 0x628 在main中printf的jalr之后的寄存器ra中有什么值? 0x38 运行以下代码。 unsigned int i = 0x00646c72; printf("H%x Wo%s", 57616, &i); He110 World 在下面的代码中,“y=”之后将打印什么(注:答案不是一个特定的值)?为什么会发生这种情况? printf("x=%d y=%d", 3); 不确定,因为参数三并没有被指定,所以此时a2寄存器是什么值就输出什么值
Backtrace 就是利用s0和ra来打印回溯函数链
1 2 3 4 5 6 7 8 9 10 11 void backtrace (void ) uint64 s0=r_fp(); uint64 kstack_base=PGROUNDDOWN(s0)+0x1000 ; while (1 ){ printf ("%p\n" ,*(uint64 *)(s0-0x8 )); s0=*(uint64 *)(s0-0x10 ); if (s0>=kstack_base){ break ; } } }
Alarm 虽然是困难级别的,但是感觉比页表那块的实验要友善很多了,就是对alarm理解的有点偏差,导致卡了一会会。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 uint64 sys_sigalarm (void ) { struct proc *p = p->alarm_handler=(void *)p->trapframe->a1; p->alarm_total_time=p->trapframe->a0; p->trapframe->a0=0 ; return 0 ; } uint64 sys_sigreturn (void ) { struct proc *p = memmove(p->trapframe,p->alarm_trapframe,sizeof (struct trapframe)); p->is_alarm=0 ; p->trapframe->a0=0 ; return 0 ; } if (p->alarm_total_time!=0 ){ p->alarm_time+=1 ; if ((p->alarm_time>=p->alarm_total_time)&&(p->is_alarm==0 )){ memmove(p->alarm_trapframe,p->trapframe,sizeof (struct trapframe)); p->trapframe->epc=(uint64)p->alarm_handler; p->alarm_handler=0 ; p->alarm_time=0 ; p->is_alarm=1 ; } }
结果 1 2 3 == Test time == time: OK Score: 85/85
结语 通过这个实验更加深刻的了解了xv6的内核和用户态之间的切换,修改起xv6相关代码也十分顺手了。
LAB5: xv6 lazy page allocation 这个实验比较简单,就是实现简单的惰性分配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 int argaddr (int n, uint64 *ip) *ip = argraw(n); char *mem; struct proc *p = uint64 va; if ((walkaddr(p->pagetable,*ip)==0 )){ if ((PGROUNDUP(p->trapframe->sp)-1 <(*ip))&&((*ip)<p->sz)){ mem=kalloc(); if (!mem){ p->killed=1 ; return -1 ; } memset (mem,0 ,PGSIZE); va=PGROUNDDOWN(*ip); if (mappages(p->pagetable, va, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R|PTE_U) != 0 ){ panic("mappages fail" ); } }else { p->killed=1 ; return -1 ; } } return 0 ; } else if (r_scause() == 13 ||r_scause() == 15 ){ uint64 bad_addr=r_stval(); char *mem=0 ; if ((bad_addr<p->sz)&&((mem=kalloc())!=0 )&&(PGROUNDUP(p->trapframe->sp)-1 <bad_addr)){ uint64 va=PGROUNDDOWN(bad_addr); memset (mem,0 ,PGSIZE); if (mappages(p->pagetable, va, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R|PTE_U) != 0 ){ panic("mappages fail" ); } }else { p->killed=1 ; }
结果 Lab6: Copy-on-Write Fork for xv6 就是实现fork时的cow机制,我的思路是在fork的时候没有w权限的直接直接复制映射,如果有w权限的符知进程的flag全部&(~PTE_W)|PTE_COW,这样PTE_COW标志就既可以判断是否是cow映射,还可以标识这个映射是有w权限的,这样就防止了子进程的权限管理不严格,比如子进程写不可写页面之类的。
由于我没有使用锁,多进程的kfree()就会出现问题hhh,但是把cow实现成功我就心满意足了,下面是代码,不过代码写的很臃肿。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 void kfree (void *pa) struct run *r ; if (((uint64)pa % PGSIZE) != 0 || (char *)pa < end || (uint64)pa >= PHYSTOP) panic("kfree" ); uint64 num=(uint64)pa; if ((--cow_num[num>>12 ])!=0 ){ return ; } memset (pa, 1 , PGSIZE); r = (struct run*)pa; acquire(&kmem.lock); r->next = kmem.freelist; kmem.freelist = r; release(&kmem.lock); } void *kalloc (void ) struct run *r ; acquire(&kmem.lock); r = kmem.freelist; if (r) kmem.freelist = r->next; release(&kmem.lock); if (r){ memset ((char *)r, 5 , PGSIZE); } uint64 num=(uint64)r; cow_num[num>>12 ]++; return (void *)r; } else if (r_scause()==15 ){ uint64 write_addr=r_stval(); uint64 va=PGROUNDDOWN(write_addr); pte_t *pte; if (write_addr<MAXVA){ pte=walk(p->pagetable,va,0 ); if ((*pte & PTE_V) == 0 ){ panic("cow usertap pte fail" ); } uint flags=PTE_FLAGS(*pte); char *mem=0 ; if (((flags|PTE_COW)!=0 )&&(write_addr<p->sz)&&((mem=kalloc())!=0 )){ uint64 pa=PTE2PA(*pte); memmove(mem,(void *)pa,PGSIZE); flags=(flags&(~PTE_COW))|PTE_W; *pte=PA2PTE(mem)|flags; kfree((void *)pa); }else { p->killed=1 ; } }else { p->killed=1 ; } copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len) { uint64 n, va0, pa0; pte_t *pte; uint flags; char *mem=0 ; while (len > 0 ){ va0 = PGROUNDDOWN(dstva); pa0 = walkaddr(pagetable, va0); if (va0<MAXVA){ pte=walk(pagetable,va0,0 ); if (pte ==0 ){ return -1 ; } flags=PTE_FLAGS(*pte); if ((flags&PTE_COW)!=0 &&((mem=kalloc())!=0 )){ uint64 pa=PTE2PA(*pte); memmove(mem,(void *)pa,PGSIZE); flags=(flags&(~PTE_COW))|PTE_W; *pte=PA2PTE(mem)|flags; kfree((void *)pa); pa0=(uint64)mem; } } if (pa0 == 0 ) return -1 ; n = PGSIZE - (dstva - va0); if (n > len) n = len; memmove((void *)(pa0 + (dstva - va0)), src, n); len -= n; src += n; dstva = va0 + PGSIZE; } return 0 ; } int uvmcopy (pagetable_t old, pagetable_t new , uint64 sz) pte_t *pte; uint64 pa, i; uint flags; for (i = 0 ; i < sz; i += PGSIZE){ if ((pte = walk(old, i, 0 )) == 0 ) panic("uvmcopy: pte should exist" ); if ((*pte & PTE_V) == 0 ) panic("uvmcopy: page not present" ); pa = PTE2PA(*pte); cow_num[(pa>>12 )]++; flags = PTE_FLAGS(*pte); if (flags&PTE_W){ *pte=(*pte)|PTE_COW; *pte=(*pte)&(~PTE_W); flags=flags|PTE_COW; flags=(flags&(~PTE_W)); } if (mappages(new , i, PGSIZE, (uint64)pa, flags) != 0 ){ panic("uvmcopy fail" ); } } return 0 ; }
结果 满分,好欸
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 os@os-virtual-machine:~/xxv6/xv6-labs-2020$ ./grade-lab-cow make: “kernel/kernel”已是最新。 == Test running cowtest == (4.9s) == Test simple == simple: OK == Test three == three: OK == Test file == file: OK == Test usertests == (107.3s) (Old xv6.out.usertests failure log removed) == Test usertests: copyin == usertests: copyin: OK == Test usertests: copyout == usertests: copyout: OK == Test usertests: all tests == usertests: all tests: OK == Test time == time: OK Score: 110/110
Lab7: Multithreading Uthread: switching between threads (moderate) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void thread_create (void (*func)()) struct thread *t ; for (t = all_thread; t < all_thread + MAX_THREAD; t++) { if (t->state == FREE) break ; } t->state = RUNNABLE; t->context.sp=(uint64)t->stack +STACK_SIZE-1 ; t->context.ra=(uint64)func; } if (current_thread != next_thread) { next_thread->state = RUNNING; t = current_thread; current_thread = next_thread; thread_switch((uint64)&(t->context),(uint64)&(current_thread->context)); struct thread { char stack [STACK_SIZE]; int state; struct context context ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 .text .globl thread_switch thread_switch: sd ra, 0(a0) sd sp, 8(a0) sd s0, 16(a0) sd s1, 24(a0) sd s2, 32(a0) sd s3, 40(a0) sd s4, 48(a0) sd s5, 56(a0) sd s6, 64(a0) sd s7, 72(a0) sd s8, 80(a0) sd s9, 88(a0) sd s10, 96(a0) sd s11, 104(a0) ld ra, 0(a1) ld sp, 8(a1) ld s0, 16(a1) ld s1, 24(a1) ld s2, 32(a1) ld s3, 40(a1) ld s4, 48(a1) ld s5, 56(a1) ld s6, 64(a1) ld s7, 72(a1) ld s8, 80(a1) ld s9, 88(a1) ld s10, 96(a1) ld s11, 104(a1) ret /* return to ra */
后面两个实验就是用户态的锁和释放,就不放代码了
结果 1 2 3 4 5 6 7 8 9 10 11 12 make: “kernel/kernel”已是最新。 == Test uthread == uthread: OK (0.9s) == Test answers-thread.txt == answers-thread.txt: OK == Test ph_safe == make: “ph”已是最新。 ph_safe: OK (10.8s) == Test ph_fast == make: “ph”已是最新。 ph_fast: OK (22.3s) == Test barrier == make: “barrier”已是最新。 barrier: OK (11.1s) == Test time == time: OK Score: 60/60
Lab8: locks 实验一 为每个cpu准备一个空闲队列,然后每个cpu在自己的空闲队列上获得新页面,然后为每个空闲队列准备一个锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 #include "types.h" #include "param.h" #include "memlayout.h" #include "spinlock.h" #include "riscv.h" #include "defs.h" void freerange (void *pa_start, void *pa_end) extern char end[]; struct run { struct run *next ; }; struct { struct spinlock lock ; struct run *freelist ; } kmem[3 ]; void kinit () initlock(&kmem[0 ].lock, "kmem0" ); initlock(&kmem[1 ].lock, "kmem1" ); initlock(&kmem[2 ].lock, "kmem2" ); freerange(end, (void *)PHYSTOP); } void freerange (void *pa_start, void *pa_end) char *p; p = (char *)PGROUNDUP((uint64)pa_start); for (; p + PGSIZE <= (char *)pa_end; p += PGSIZE) kfree(p); } void kfree (void *pa) struct run *r ; uint32 keme_id; if (((uint64)pa % PGSIZE) != 0 || (char *)pa < end || (uint64)pa >= PHYSTOP){ printf ("pa : %p\n" ,(uint64)pa); panic("kfree" ); } memset (pa, 1 , PGSIZE); r = (struct run*)pa; keme_id=(((uint64)pa)>>12 )%3 ; acquire(&kmem[keme_id].lock); r->next = kmem[keme_id].freelist; kmem[keme_id].freelist = r; release(&kmem[keme_id].lock); } void *get_other_freeelist_r (uint32 kmem_id) struct run *r ; acquire(&kmem[kmem_id].lock); r = kmem[kmem_id].freelist; if (r) kmem[kmem_id].freelist = r->next; release(&kmem[kmem_id].lock); return (void *)r; } void *kalloc (void ) struct run *r ; uint32 keme_id; keme_id=cpuid(); acquire(&kmem[keme_id].lock); r = kmem[keme_id].freelist; if (r) kmem[keme_id].freelist = r->next; release(&kmem[keme_id].lock); if (!r){ r=get_other_freeelist_r((keme_id+1 )%3 ); if (!r){ r=get_other_freeelist_r((keme_id+2 )%3 ); } } if (r) memset ((char *)r, 5 , PGSIZE); return (void *)r; }
实验二 在xv6操作系统中,会有一个缓冲区列表来记录磁盘内容,当读磁盘的时候,首先会把内容缓冲到这个缓冲区,然后再从这个缓冲区中读取信息,刚开始这个缓冲区全部放在一个链表中然后使用一个锁防止竞争,但是io吞吐量比较大的时候是比较浪费cpu资源的,所以得让数据结构更加细化,选择使用一个桶(但感觉和哈希表没啥差别)来整多个链表,然后每个链表一个锁来保护,这样既能防止竞争,又能更加线程化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 #define Bucket_size 13 #define HASH(id) (id%13) #include "types.h" #include "param.h" #include "spinlock.h" #include "sleeplock.h" #include "riscv.h" #include "defs.h" #include "fs.h" #include "buf.h" struct bucket { struct spinlock lock ; struct buf head ; }; struct { struct buf buf [NBUF ]; struct bucket buckets [13]; } bcache; char lockname[16 ][16 ];char b_lockname[30 ][16 ];void binit (void ) struct buf *b ; memset (lockname,0 ,sizeof (lockname)); memset (b_lockname,0 ,sizeof (b_lockname)); for (int i=0 ;i<Bucket_size;i++){ snprintf (lockname[i],sizeof (lockname),"bcahce_%d" ,i); initlock(&(bcache.buckets[i].lock),lockname[i]); } for (int i=0 ;i<Bucket_size;i++){ bcache.buckets[i].head.prev=&bcache.buckets[i].head; bcache.buckets[i].head.next=&bcache.buckets[i].head; } int i=0 ; for (b = bcache.buf; b < bcache.buf+NBUF; b++){ b->next = bcache.buckets[0 ].head.next; b->prev = &bcache.buckets[0 ].head; snprintf (b_lockname[i],sizeof (b_lockname),"buffer_%d" ,i); initsleeplock(&b->lock,b_lockname[i]); bcache.buckets[0 ].head.next->prev = b; bcache.buckets[0 ].head.next = b; i++; } } static struct buf*bget (uint dev, uint blockno) struct buf *b ; struct buf *tmp ; uint32 bid; bid=HASH(blockno); tmp=0 ; acquire(&bcache.buckets[bid].lock); for (b=bcache.buckets[bid].head.next;b!=&bcache.buckets[bid].head;b=b->next){ if (dev==b->dev&&blockno==b->blockno){ b->refcnt++; acquire(&tickslock); b->timetick = ticks; release(&tickslock); release(&bcache.buckets[bid].lock); acquiresleep(&b->lock); return b; } } b=0 ; for (int i=bid,cur=0 ;cur<Bucket_size;i=(i+1 )%Bucket_size){ cur++; if (i!=bid){ if (!holding(&bcache.buckets[i].lock)){ acquire(&bcache.buckets[i].lock); }else { continue ; } }else { continue ; } for (b=bcache.buckets[i].head.next;b!=&bcache.buckets[i].head;b=b->next){ if (b->refcnt==0 &&((b->timetick<tmp->timetick)||tmp)){ tmp=b; } } if (tmp){ tmp->next->prev=tmp->prev; tmp->prev->next=tmp->next; release(&bcache.buckets[i].lock); tmp->next=bcache.buckets[bid].head.next; tmp->prev=&bcache.buckets[bid].head; bcache.buckets[bid].head.next->prev=tmp; bcache.buckets[bid].head.next=tmp; tmp->dev = dev; tmp->blockno = blockno; tmp->valid = 0 ; tmp->refcnt = 1 ; acquire(&tickslock); tmp->timetick = ticks; release(&tickslock); release(&bcache.buckets[bid].lock); acquiresleep(&tmp->lock); return tmp; }else { release(&bcache.buckets[i].lock); } } panic("bget: no buffers" ); } struct buf* bread (uint dev, uint blockno) struct buf *b ; b = bget(dev, blockno); if (!b->valid) { virtio_disk_rw(b, 0 ); b->valid = 1 ; } return b; } void bwrite (struct buf *b) if (!holdingsleep(&b->lock)) panic("bwrite" ); virtio_disk_rw(b, 1 ); } void brelse (struct buf *b) uint32 bid; bid=HASH(b->blockno); if (!holdingsleep(&b->lock)) panic("brelse" ); releasesleep(&b->lock); acquire(&bcache.buckets[bid].lock); b->refcnt--; acquire(&tickslock); b->timetick = ticks; release(&tickslock); release(&bcache.buckets[bid].lock); } void bpin (struct buf *b) uint32 bid=HASH(b->blockno); acquire(&bcache.buckets[bid].lock); b->refcnt++; release(&bcache.buckets[bid].lock); } void bunpin (struct buf *b) uint32 bid=HASH(b->blockno); acquire(&bcache.buckets[bid].lock); b->refcnt--; release(&bcache.buckets[bid].lock); }